












Fri, 12 Jan 2024
# Heaplog - Search For Local Log Files
Table of Contents
At work we have quite simple deployment setup - one huge server where all our services run as docker container. Logs are collected in a single folder. At some point we decided to have a solution for log search to help in debugging issues. And there this journey has begun.
We tried surprisingly many solutions just to find out that nothing works as seamlessly as we want. We tried ELK stack, which is too huge for our use-case, needs complex setup and resources. We tried some other solutions like graylog, eventually we settled on a regexp-based search app that does the job, but fails if files become bigger than a few Gb. I was deeply unsatisfied with this situation, how hard can it be to have a search for logs? I asked and turned out it was hard, especially if don't you know what you are doing. So I decided to understand this problem and design a search program. So here it is - Heaplog.
# Design Exploration
Assuming we have gigabytes of logs, simple regexp full-scan won't be reasonable in terms of time and resources consumption. So the logs must be indexed somehow and searches must be reasonably quick. Also I wanted to keep the index small on disk, and modest on resources. Logs are streams of messages, so indexing is not a one-time thing, but regular work, so the search must reside in memory and index new pieces of logs as they appear. Often older logs are removed, so the search must drop parts of the index that are no longer needed. It must offer Web UI for making searches and browse results. That was my initial requirements.
# Heap Files And Small Index
To keep the index small I applied a few ideas. Firstly, it supports only exact match, so the index keeps a simple inverted index of all terms found in the messages. Shorter terms are skipped (<4 symbols), longer terms are trimmed (> 20 symbols).
Secondly, it keeps sparse inverted index. It means that terms point not to individual messages, but to segments of files. In other words, it keep information that the term "error" exists somewhere in the 50Mb segment of a file.
The index does not contain original messages, only the meta information about them, while original data is kept in the files. Which are often called "heap files", so that is why the program called "heaplog".
Choosing the storage was tricky. My first attempt was using Sqlite. Expectedly, row-based db is not really suitable for analytical data:
Trying to figure out how to use SQLite as an (inverted) index for text files. SO far managed to index a 2Gb file and get 3.5Gb index, LoL...
— Dmitriy Lezhnev (@dimalezhnev) June 15, 2023
I used sqlite to keep the database within my app address space, and not to introduce a separate process to manage data. Luckily, there is a great analytical in-process database called Duckdb. It worked much better. It is a column-oriented storage that can compress data quite well.
# Inverted Index
The heart of the search is its index. The heart of the text index is... inverted index. This one deserves a dedicated discussion, you can read my earlier post about that.
One of the challenges here is efficient ingestion of indexed data. File segments are indexed concurrently and each pushes it's chunk of terms found in the segment. Terms can duplicate in segments, so uniqueness checks must apply. But that is not feasibly in terms of performance, so instead each segment produces its own inverted index (fast and concurrently), which is later merged with others in the background to make a single inverted index. That is the same idea as seen in LSM-trees.
Notably, FST data structure is such and efficient way of storing unique terms in the index. I never knew about it before.
# Search Query Language
To support different search use-cases I added a custom query language. The parser is done with Antlr and the language specification can be seen here.
It supports both "exact match" operations as well as regualr expressions. The latter obviously can't use the index and do full scan. To make it scan less, usually it is better to substitute a re query with some exact match terms, so it can use the index and reduce the surface of scanning.
The given query is tokenized with the same tokenizer as the indexer uses, so the resulting terms are the same as used in indexing.
# Search Flow
The search happens in steps. First, it parses the query and makes an expression internal representation (a tree). Then it tokenizes the expression and extracts terms from it. Then it uses the inverted index to find relevant file segments that will be used for scanning. After that, it reads every segment, splits messages and match every message against the expression.
In other words, the search happens in 2 phases:
- Selection of relevant file segments.
- Matching messages in the segments.
If terms are too small (<4 symbols) or only regular expression is given, it select all segments for matching, which is a full-scan scenario. Slow.
Also, it tries to return early. Whenever the first page of results is ready it will render results before the user, while keeping searching in the background.
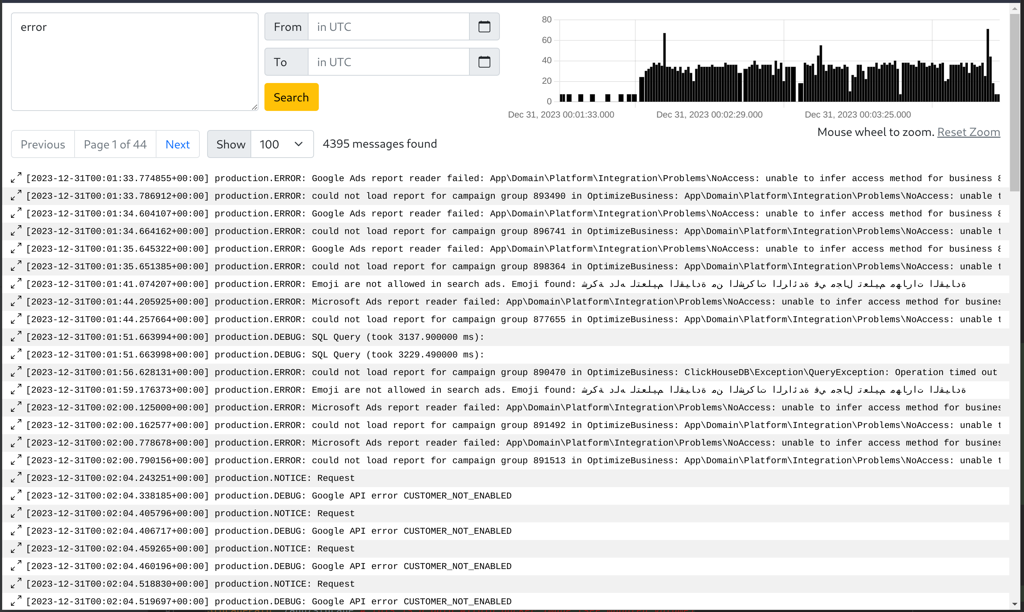
# Web UI And HTMX
In my head UI must support seamless interactions. We start with one query, browse results, change pages, refine the query and continue until we got enough data. Waiting for page reload on each click was not something I wanted. On the other hand, I did not feel like using React or something like that for the job. The middle ground was HTMX which is a server-side rendering tool, with a bit of JS that allows reloading fragments of the page seamlessly.
After using it for a few days, it felt good as everything happens on the backend, but still certain skill must be developed to use the full potential of the tool.
One notable feature is the Timeline at the right top. It proved to be a handy tool, it shows how matches spread across time. Also, you can use your mouse to zoom in to certain time window and inspect those messages. That helps with data exploration and debugging greatly.
# Conclusion
Making search engines is not easy. Practically, it is easier to configure something that exists already, be it Lucene, ELK-stack or whatever. However, for educational purposes it makes total sense to create one from scratch. That is what I did and enjoyed every step on the way, every frustration moment when things don't work and epiphany once they do.